

Способ №2
1. Кликните по редактируемой таблице.
2. На вкладке «Данные», в блоке «Сортировка и фильтр», щёлкните подраздел «Дополнительно».
Если необходимо создать новую таблицу, содержащую только уникальные ячейки исходника:
1. В панели «Расширенный фильтр» клацните радиокнопку «Скопировать результат в другое место».
2. Нажмите кнопку, расположенную в правой части поля «Поместить результат в диапазон».
3. Клацните на свободном рабочем пространстве Excel, куда необходимо будет поместить отфильтрованную таблицу. После щелчка в поле появится код ячейки. Закройте его и перейдите в опции фильтра.
4. Кликните окошко «Только уникальные записи» и нажмите «OK».
5. После выполнения фильтрации в указанном месте появится версия исходной таблицы без повторов.
Чтобы отредактировать документ без создания копий:
- в панели «Расширенный фильтр» установите режим обработки «Фильтровать список на месте»;
- кликом мышки включите надстройку «Только уникальные записи»;
- клацните «OK».
Доброго времени суток!
С популяризацией компьютеров за последние 10 лет — происходит и популяризация создания отчетов (документов) в программе Excel.
И в любом относительно большом документе встречаются повторяющиеся строки, особенно, если вы его собрали из несколько других таблиц. Эти дубли могут очень мешать дальнейшему редактированию таблицы, а потому их нужно либо выделить, либо вообще удалить…
Собственно, ко мне ни раз и ни два обращались с подобными вопросами, и я решил оформить работу с дубликатами в отдельную небольшую статью (которую вы сейчас читаете). Приведу самые часто-встречаемые задачи, и покажу их решение.
Примечание
: все примеры ниже будут представлены в Office 2016 (актуально также для Office 2013, 2010, 2007). Рекомендую всегда использовать относительно новые версии Office: в них и быстрее работать, и проще ☻.
Выделяем цветом дубликаты в таблице
Первым способом я покажу вам, каким образом можно найти дубликаты и выделить их цветом. Это может вам потребоваться, для сравнения каких-либо данных без их удаления. В моем примере это будут одинаковые имена и фамилии людей.
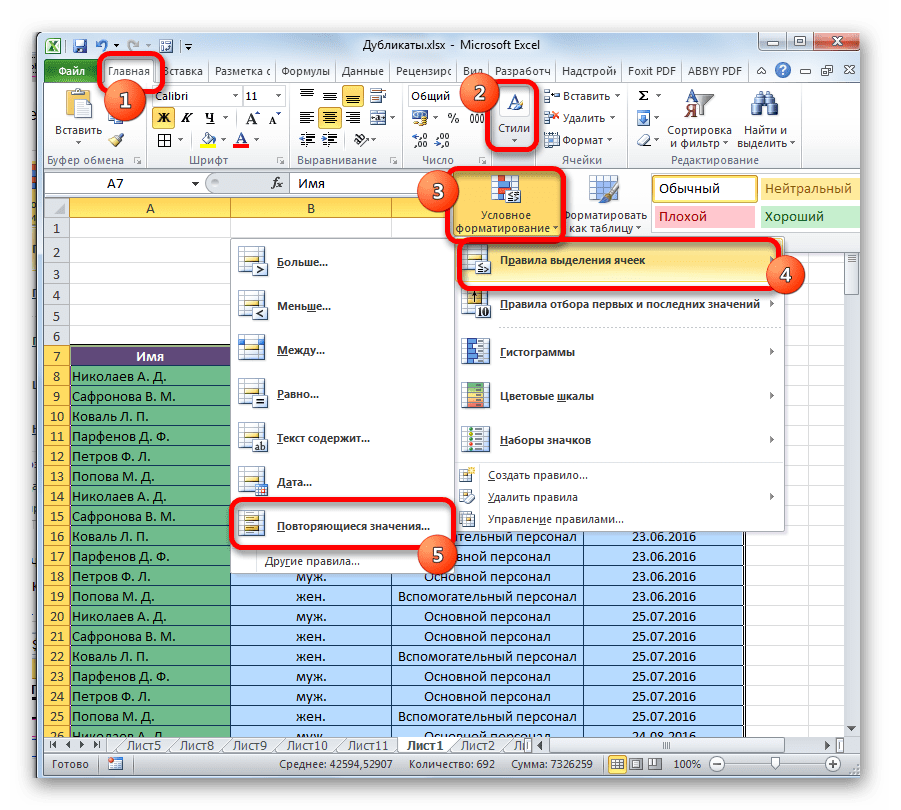
Открывает вкладку «Главная», в разделе «Стили» выбираем «Условное форматирование» — «Правила выделения ячеек» — «Повторяющиеся значения».
Открылось окно, в котором есть два пункта: что выделить – уникальные или повторяющиеся значения, и, как их выделить – в какую цветовую гамму. И, конечно же, кнопка «ОК».
Посмотрите на мой результат. Правда такой способ имеет существенный недостаток: нет выборки, выделяет все, что встречается более одного раза.
Удаление Дубликатов по Нескольким Критериям
Давайте вернемся, к казалось бы, простому меню, которое у нас выскакивает при выделенных данных. В этом списке представлены все колонки нашей Excel таблицы. Вы можете заметить, что каждой колонке соответствует свой чекбокс.
Зачем нам нужно это меню? Главным образом, оно позволят нам уточнить для Excel, каким образом будут удалять повторы. Давайте рассмотрим пример:
Пример Удаления Дубликатов по одному фактору.
На скриншоте выше, я опять выделили данные и нажал на кнопку Удалить Дубликаты. Затем, я снял выделения в чекбоксах, за исключением одного — «Chef». Результат показан в нижней половине картинки. Заметьте, что наша таблица уменьшилась всего на три строки, на те в которых повторялось имя шефа.
Когда мы отмечаем только чекбокс с названием «Chef», мы просим Excel, искать повторы только в колонке Chef. Первый раз, как он видит повторяющееся имя в колонке chefe, то он удаляет целую строку, в независимости от того, чем отличаются другие колонки.
Будьте Осторожны Удаляя Повторяющиеся Строки в Excell
И вот почему так важно соблюдать осторожность при использовании функции «Удалить Дубликаты». Если вы оставите удаление по одному фактору, то вы можете случайно удалить данные, которые на самом деле нужны
Совет: окошки, которые вы оставляете отмеченными в окне Удаления Дубликатов — это комбинации по которым Excel будет проверять повторы. Оставляйте отмеченными несколько чекбоксов, для более аккуратного удаления.
Часто, одной колонки не достаточно, что бы достоверно судить о наличии повторов. Если у вас есть онлайн магазин, и вы ведете базу данных по покупателям, велики шансы, что среди ваши данных есть более чем одно упоминание покупателя «Mike Smith». Вы должны отмечать несколько колонок, для правильного удаления дубликатов, такие как имя покупателя, его адрес или дата регистрации. Вот почему мы отмечаем несколько колонок.
Если вы хотите, чтобы удаление повторов было более точным, оставляйте отмеченными несколько чекбоксов (колонок), когда используете функцию Удалить Дубликаты. И кончено же, всегда дважды проверьте ваши данные, после использования этой функции.
Когда Нужно Быть Избирательным
Если вы используете таблицу с примерами, откройте вкладку Duplicate Shifts, для этой части урока.
Вы можете задаться вопросом: а может быть ситуация, где вам действительно придется снять галочки с каких-то окошек? Конечно может. Давайте рассмотрим следующий пример.
В таблице ниже у меня есть данные о рабочей смене сотрудников, и я случайно загрузил данные два раза. Для каждого сотрудника есть время прихода и ухода, и плюс к этому есть колонка с датой, когда я загрузил отчет. Присутствуют повторы для каждой строки, за исключением одной колонки F, где стоит Дата Загрузки Отчета.
Мне необходимо удалить повторы, потому что отчет был ошибочно загружен дважды (посмотрите на последнюю колонку), но мне нужно исключить последнюю колонку из проверок по дубликатам.
Давайте подумаем: если я отмечу все колонки для поиска повторов, Excel не найдет дубликатов. Но, я на самом деле хочу удалить повторы в рабочих сменах
Мне на самом деле не важно, в какой день я загрузил отчет, поэтому я должен исключить колонку F, при оценке повторяющихся строк
Мои строки почти что те же; отличия только в колонке F, я не хочу, чтобы Excel оценивал ее при поиске повторов. Если я оставлю галочки во всех чекбоксах, Excel вообще не найдет повторов.
Эти строки не совсем повторы — в них не все повторяется, но мне нужно удалить дубликаты, основываясь на данных в колонках A-E.
Что бы сделать это, я снова выделяю таблицу и снова запускаю функцию Удалить Дубликаты. На этот раз, я оставил отмеченными все чекбоксы, за исключением Report Download Date (дата загрузки отчета).
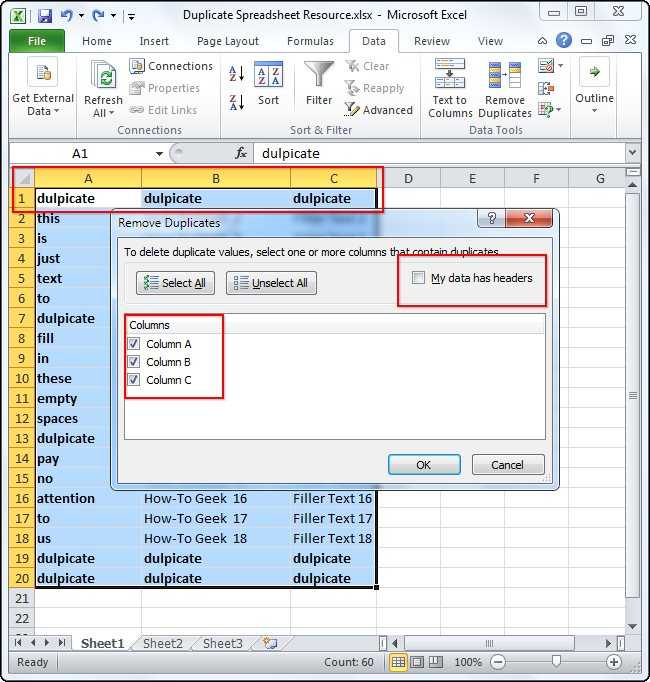
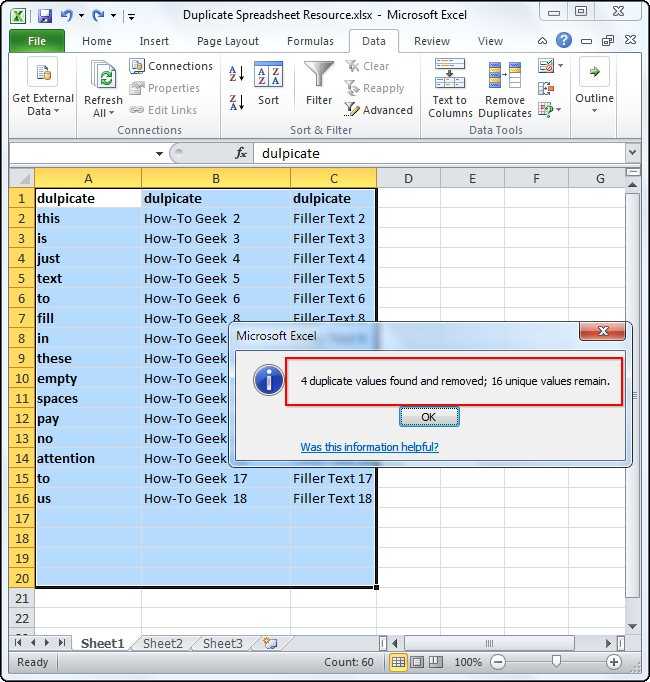

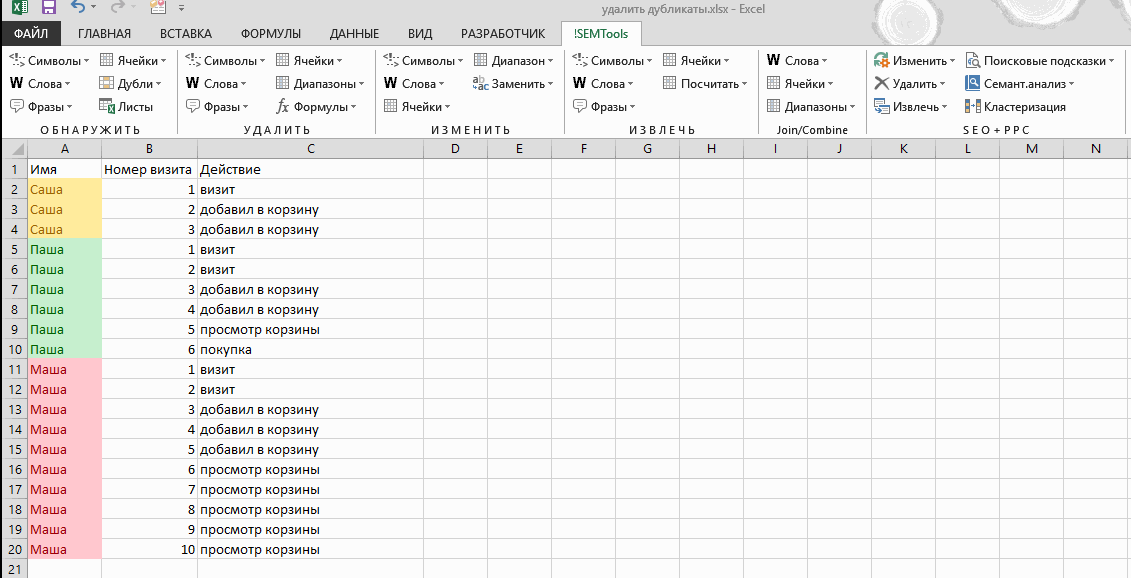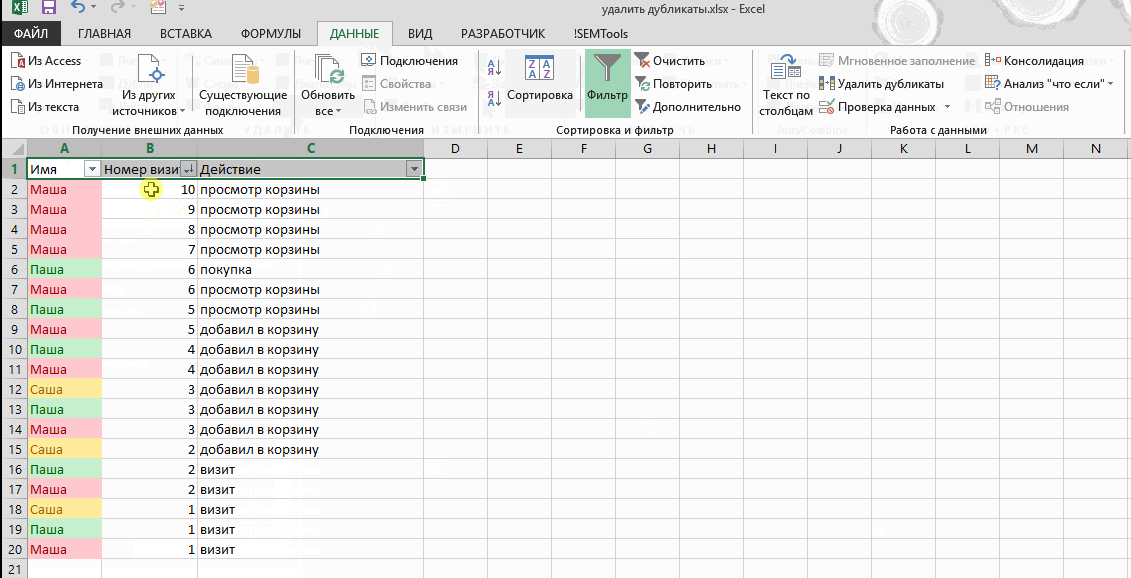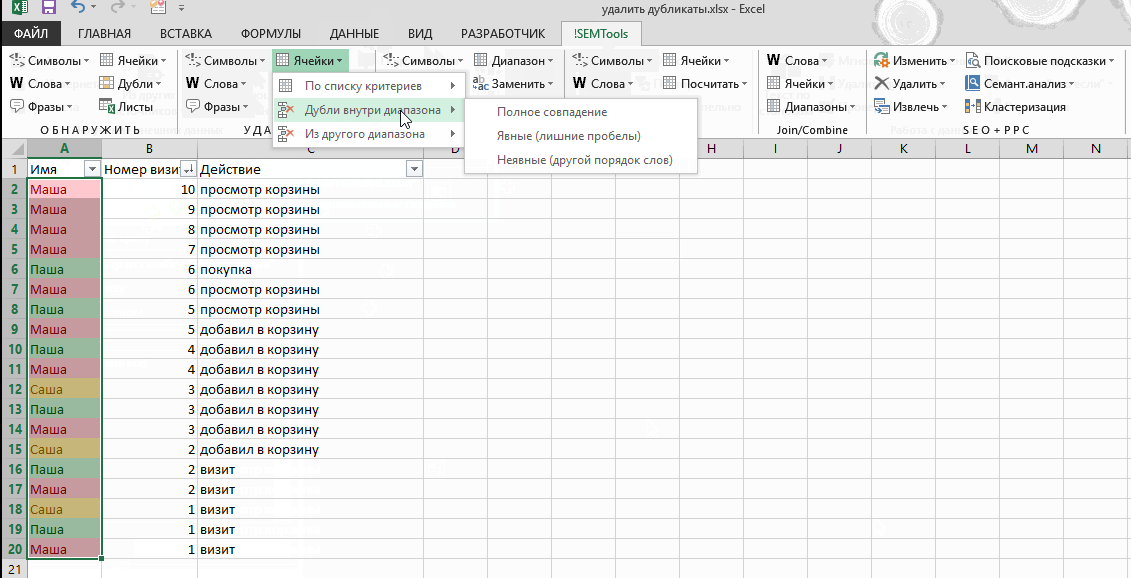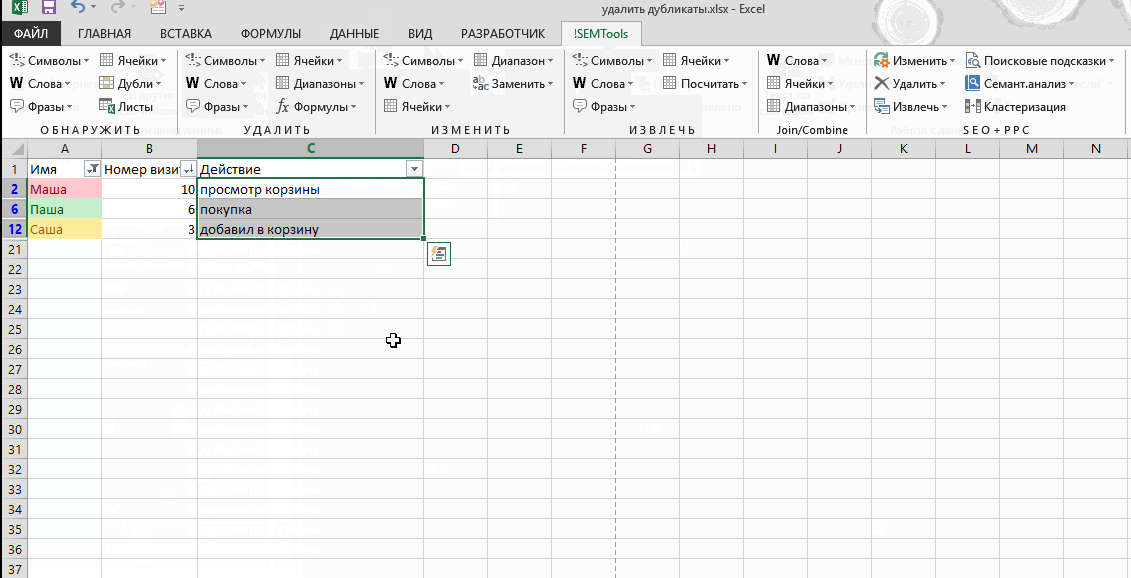
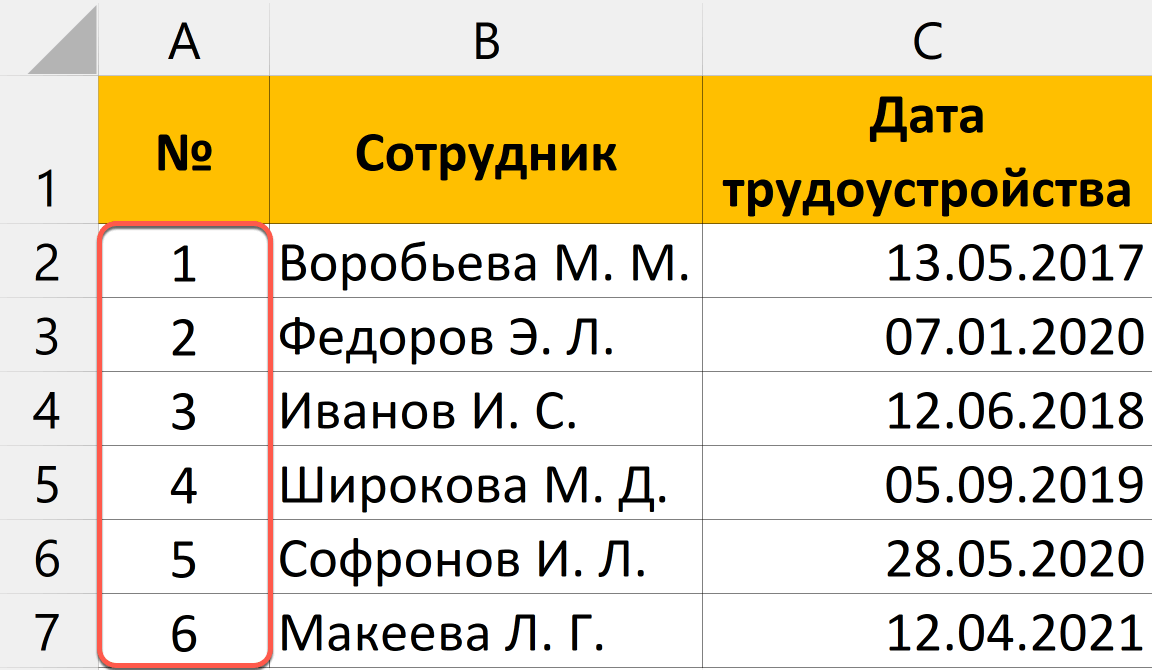
Заметьте, что Excel удалил дубликаты, потому что он игнорировал и не стал проверять в процессе работы алгоритма колонку F.
Вы можете представить себе это таким образом: те чекбоксы которые вы оставили отмеченными, соответствуют тем колонкам, которые Excel стал рассматривать в ходе поиска повторов. Если есть особые колонки, в которых не надо искать дубликаты, то снимите соответствующие галочки в окне Удалить Дубликаты.
Удаляем все одинаковые значения в Excel с помощью расширенного фильтра
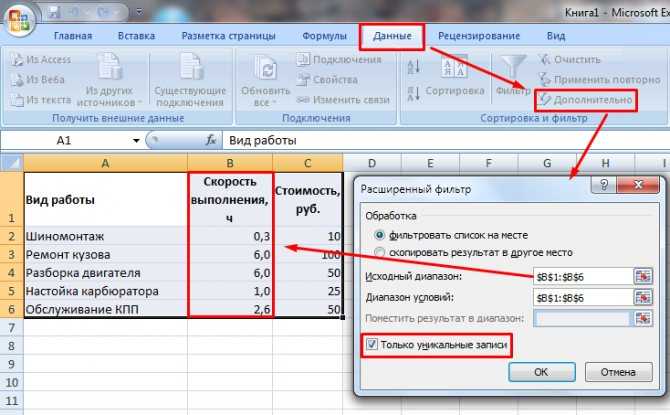
Для использования расширенного фильтра, выберем любую ячейку в таблице. Я выбрал верхнюю левую. Затем открываем вкладку «Данные», переходим в раздел «Сортировка и фильтр», и жмем по кнопке «Дополнительно».
![]()
Теперь нужно настроить в этом окне, каким образом будет произведена фильтровка. Можно скопировать результаты фильтра в другое место (ставим галочку и указываем место, куда скопируется результат), либо результат оставить в том же месте. И, обязательно, ставим галочку «Только уникальные значения».
![]()
Вот мой результат применения к таблице расширенного фильтра. Как видим, в результате Excel смог найти и удалить дубликаты.
![]()
Удалить дубликаты строк в Excel с помощью формул и фильтра
Еще один способ удалить дубликаты в Excel — это определить их с помощью формулы, отфильтровать и удалить дубликаты строк.
Преимуществом этого подхода является универсальность — он позволяет найти и удалить дубликаты в столбце или дублировать строки на основе значений в нескольких столбцах. Недостатком является то, что вам нужно будет запомнить несколько повторяющихся формул.
- В зависимости от вашей задачи используйте одну из следующих формул для поиска дубликатов.
Формулы для поиска дубликатов в 1 столбце
Дубликаты за исключением 1-го вхождения:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A2; $A2)>1; «Дубликат»; «»)
Дубликаты с 1-го вхождения:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$10; $A2)>1; «Дубликат»; «Уникальное»)
Где ячейка A2 является первой, а A10 — последней ячейкой диапазона для поиска дубликатов.
Формулы для поиска дубликатов строк
Дубликаты строк, кроме 1-го вхождения. То есть, если в результате есть две или более одинаковых строки, то первая из них будет отмечена, как уникальная, а все последующие как дубликаты:
=ЕСЛИ(СЧЁТЕСЛИМН($A$2:$A2; $A2; $B$2:$B2; $B2; $C$2:$C2; $C2)>1;»Дубликат строки»; «Уникальное»)
Дубликаты строк с 1-ым вхождением. В данном случае, если в результате поиска есть две или более одинаковых строк, то все они будут отмечены как дубликаты:
=ЕСЛИ(СЧЁТЕСЛИМН($A$2:$A$10; $A2; $B$2:$B$10; $B2; $C$2:$C$10; $C2)>1; «Дубликат строки»; «Уникальное»)
Где A, B и C — столбцы, подлежащие проверке на дубликаты.
Например, так вы можете идентифицировать дубликаты строк, за исключением 1-го вхождения:
Удалить дубликаты в Excel – Формула для идентификации дубликатов строк за исключением первых случаев
- Выберите любую ячейку в своей таблице и примените автоматический фильтр, нажав кнопку «Фильтр» на вкладке «ДАННЫЕ», или «Сортировка и фильтр» —> «Фильтр» на вкладке «ГЛАВНАЯ».
Удалить дубликаты в Excel – Применение фильтра к ячейкам (Вкладка ДАННЫЕ)
- Отфильтруйте дубликаты строк, щелкнув стрелку в заголовке столбца «Дубликаты», а затем установите флажок «Дубликат строки».
Удалить дубликаты в Excel – Фильтр дубликатов строки
- И, наконец, удалите дубликаты строк. Чтобы сделать это, выберите отфильтрованные строки, переместив указатель мыши на номера строк, щелкните по ним правой кнопкой мыши и выберите «Удалить строку» в контекстном меню. В данном случае для удаления дубликатов не стоит пользоваться клавишей «Delete» на клавиатуре, потому что нам необходимо удалить целые строки, а не только содержимое ячеек:
Удалить дубликаты в Excel – Фильтрация и удаление дубликатов строк
Ну, теперь вы узнали несколько способов, как удалить дубликаты в Excel. И можете пользоваться одним из них в зависимости от вашей ситуации.
Поиск и выделение дубликатов цветом
Чтобы выделить дубликаты на фоне других ячеек каким-то цветом, надо использовать условное форматирование. Этот инструмент имеет множество функций, в том числе, и возможность выставлять цвет для обнаруженных дубликатов.
В одном столбце
Условное форматирование – это наиболее простой способ определить, где находятся дубликаты в Excel и выделить их. Что нужно сделать для этого?
- Найти ту область поиска дубликатов и выделить ее. 13
- Переключить свой взор на Панель инструментов, и там развернуть вкладку «Главная». После нажатия на эту кнопку появляется набор пунктов, и нас, как уже было понятно исходя из информации выше, интересует пункт «Повторяющиеся значения».
14
- Далее появляется окно, в котором нужно выбрать пункт «Повторяющиеся» и нажать на клавишу ОК.
15
Теперь дубликаты подсвечены красным цветом. После этого нужно их просто удалить, если в этом есть необходимость.
В нескольких столбцах
Если стоит задача определить дубликаты, расположенные больше, чем в одной колонке, то принципиальных отличий от стандартного использования условного форматирования нет. Единственная разница заключается в том, что необходимо выделить несколько столбцов.
Последовательность действий, в целом, следующая:
- Выделить колонки, в которых будет осуществляться поиск дубликатов.
- Развернуть вкладку «Главная». После этого находим пункт «Условное форматирование» и выставляем правило «Повторяющиеся значения» так, как это было описано выше.
- Далее снова выбираем пункт «Повторяющиеся» в появившемся окошке, а в списке справа выбираем цвет заливки. После этого кликаем по «ОК» и радуемся жизни. 16
Дубликаты строк
Важно понимать, что между поиском дублей ячеек и строк есть огромная разница. Давайте ее рассмотрим более подробно
Посмотрите на эти две таблицы.
17 18
Характерная особенность тех таблиц, которые были приведены выше, заключается в том, что в них приводятся одни и те же значения. Все потому, что в первом примере осуществлялся поиск дубликатов ячеек, а во втором видим уже повторение строк с информацией.
Итак, что нужно сделать для поиска повторяющихся значений в рядах?
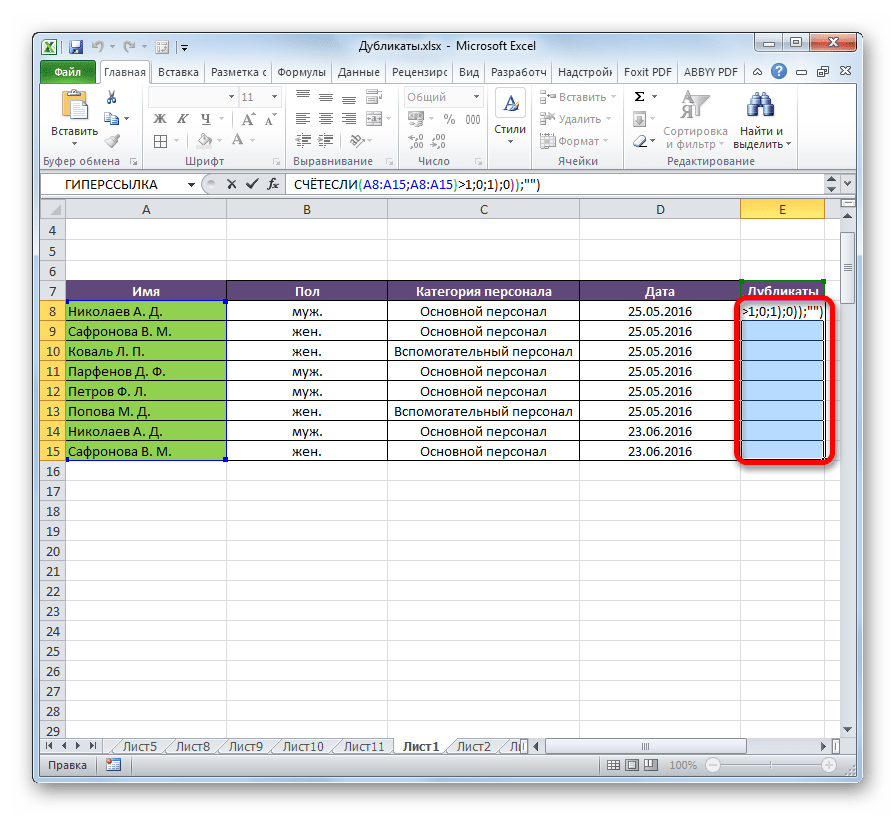
- Создаем еще одну колонку в правой части по отношению к таблице с исходной информацией. В нем записывается формула, которая выводит объединенную информацию со всех ячеек, входящих в состав строки. =A2&B2&C2&D2
- После этого мы увидим информацию, которая была объединена.
19
- После этого следует выбрать дополнительную колонку (а именно, те ячейки, которые содержат объединенные данные).
- Далее переходим на «Главная», а затем снова выбираем пункт «Повторяющиеся значения» аналогично описанному выше.
- Далее появится диалоговое окно, где снова выбираем пункт «Повторяющиеся», а в правом перечне находим цвет, с использованием которого будет осуществляться выделение.
После того, как будет нажата кнопка «ОК», повторы будут обозначены тем цветом, который пользователь выбрал на предыдущем этапе.
Хорошо, предположим, перед нами стоит задача выбрать те строки, которые располагаются в исходном диапазоне, а не по вспомогательной колонке? Чтобы это сделать, нужно предпринять следующие действия:
- Аналогично предыдущему примеру, делаем вспомогательную колонну, где записываем формулу объединения предыдущих столбцов. =A2&B2&C2&D2
- Далее мы получаем все содержащиеся в строке значения, указанные в соответствующих ячейках каждой из строк.
20
- После этого осуществляем выделение всей содержащиеся информации, не включая дополнительный столбец. В случае с нами это такой диапазон: A2:D15. После этого переходим на вкладку «Главная» и выбираем пункт «Условное форматирование» – создать правило (видим, что последовательность немного другая).
21
- Далее нас интересует пункт «Использовать формулу для определения форматируемых ячеек», после чего вставляем в поле «Форматировать значения, для которых следующая формула является истинной», такую формулу. =СЧЁТЕСЛИ($E$2:$E$15;$E2)>1
22
Для дублированных строк обязательно установить правильный формат. С помощью приведенной выше формулы можно осуществить проверку диапазона на предмет наличия повторов и выделить их определенным пользователем цветом в таблице.
23
Как определить дубликаты в таблице
Сначала предлагаю быстро разобраться с тем, как определить наличие дубликатов в столбце. Для этого подойдет одно из правил условного форматирования. Оно подсветит строки со встречающимися повторами, и вы сможете понять, нужно ли что-то из этого удалить для оптимизации таблицы.
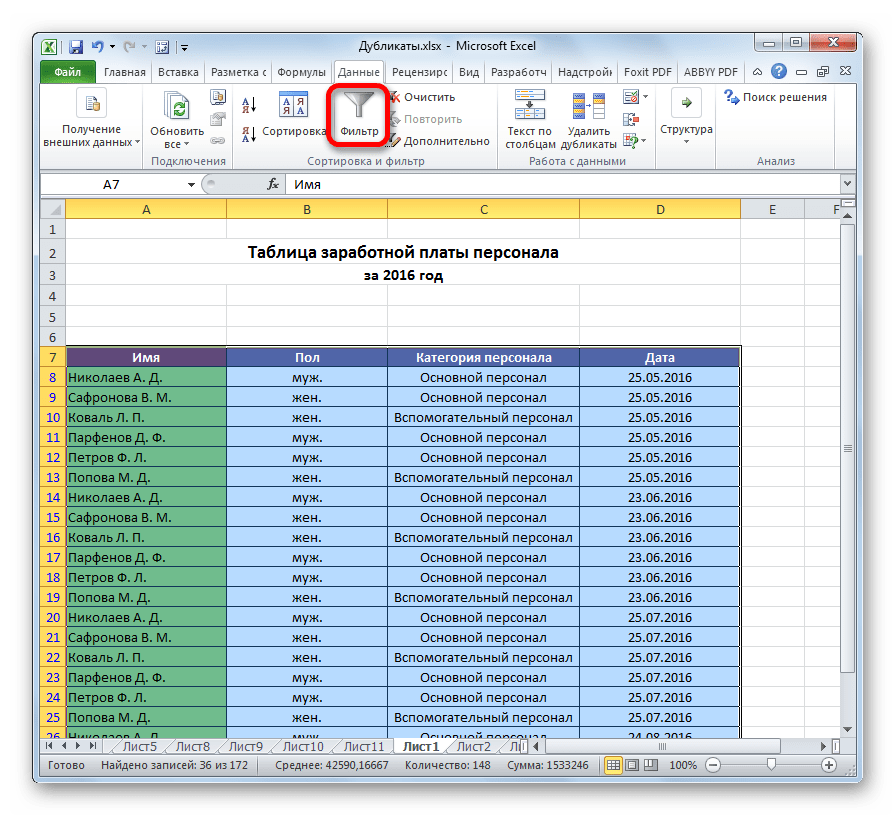
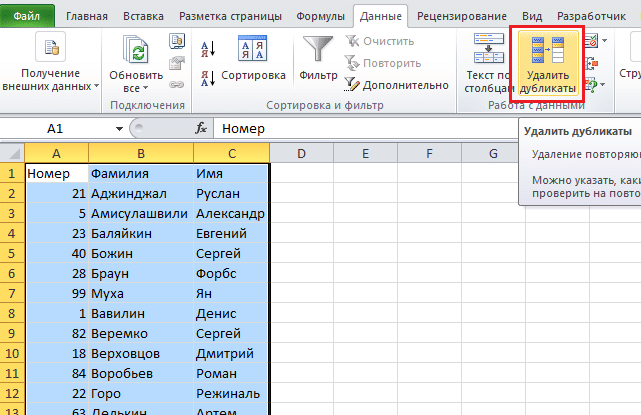
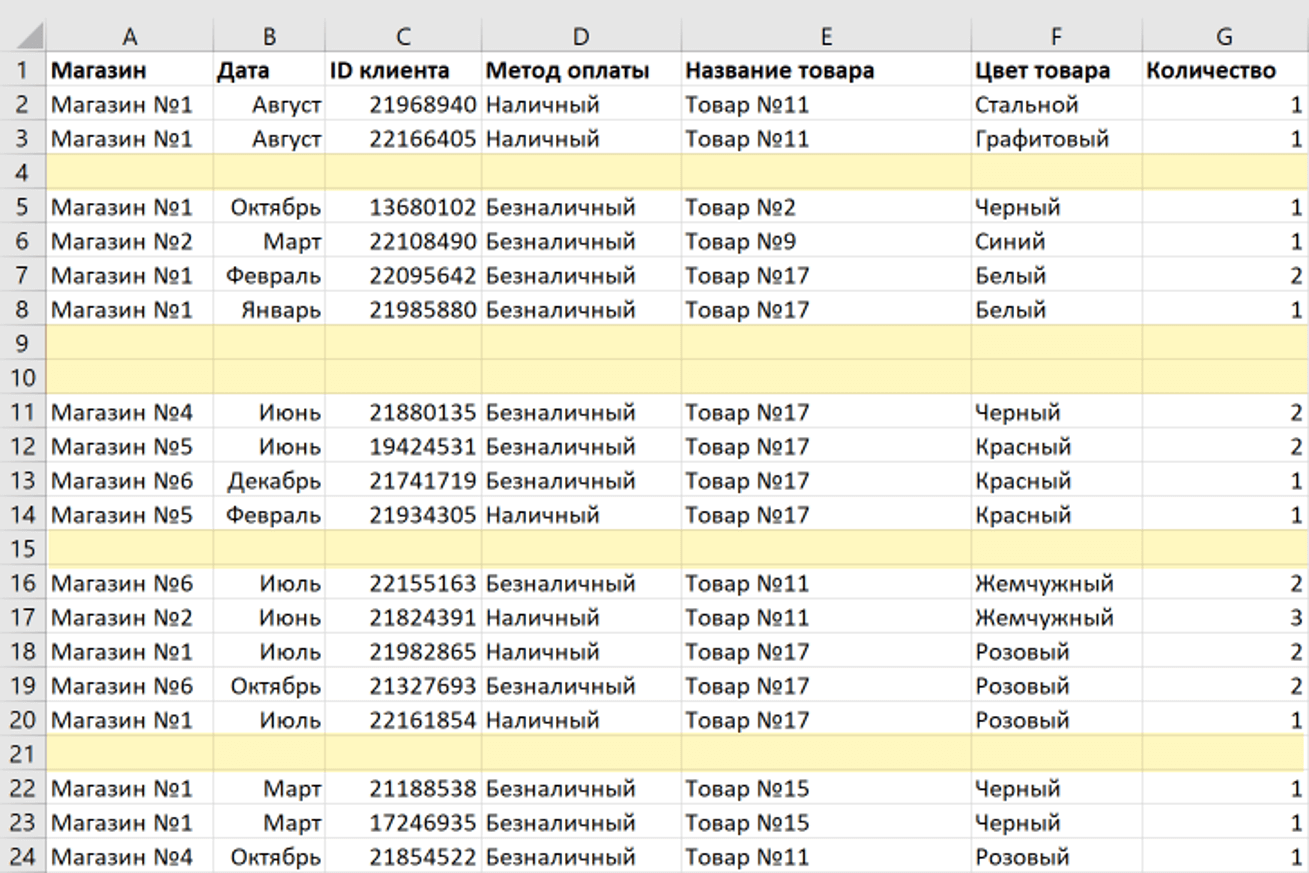
Выделите диапазон с данными и на вкладке «Главная» вызовите меню «Условное форматирование».
Наведите курсор на список правил «Правила выделения ячеек» и выберите вариант из списка «Повторяющиеся значения».
Можно изменить цвет выделения, но подойдет и стандартный
Просто подтвердите действие.
Обратите внимание на то, что ячейки с повторами выделены цветом, а уникальные значения остаются неподсвеченными. Теперь вы знаете точно, какие данные повторяются и можно ли их удалить.
Это лишь один из примеров условного форматирования в Microsoft Excel. Если вас заинтересовала эта тема, читайте другую мою статью, где рассказано все о данной функции.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Удаление повторяющихся значений в Excel (2007+)
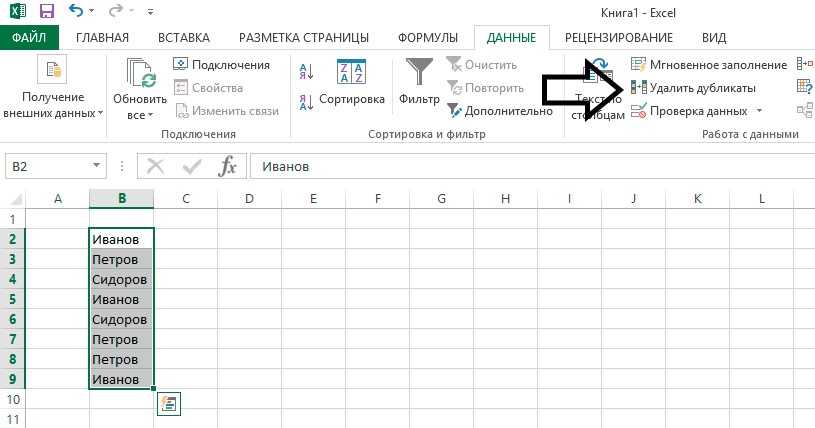
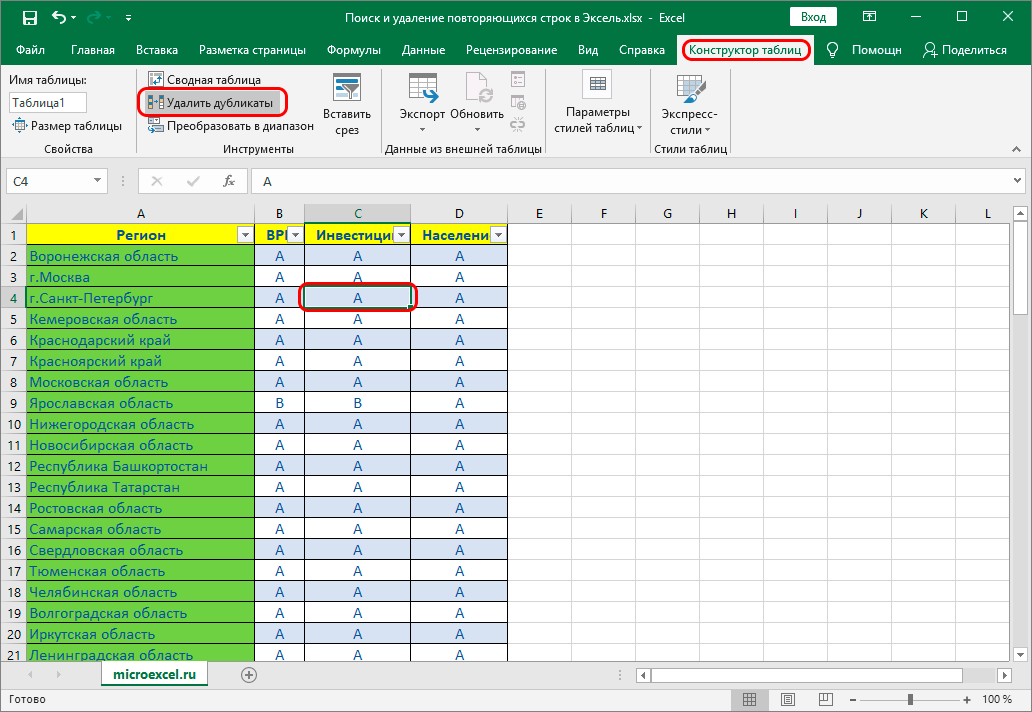
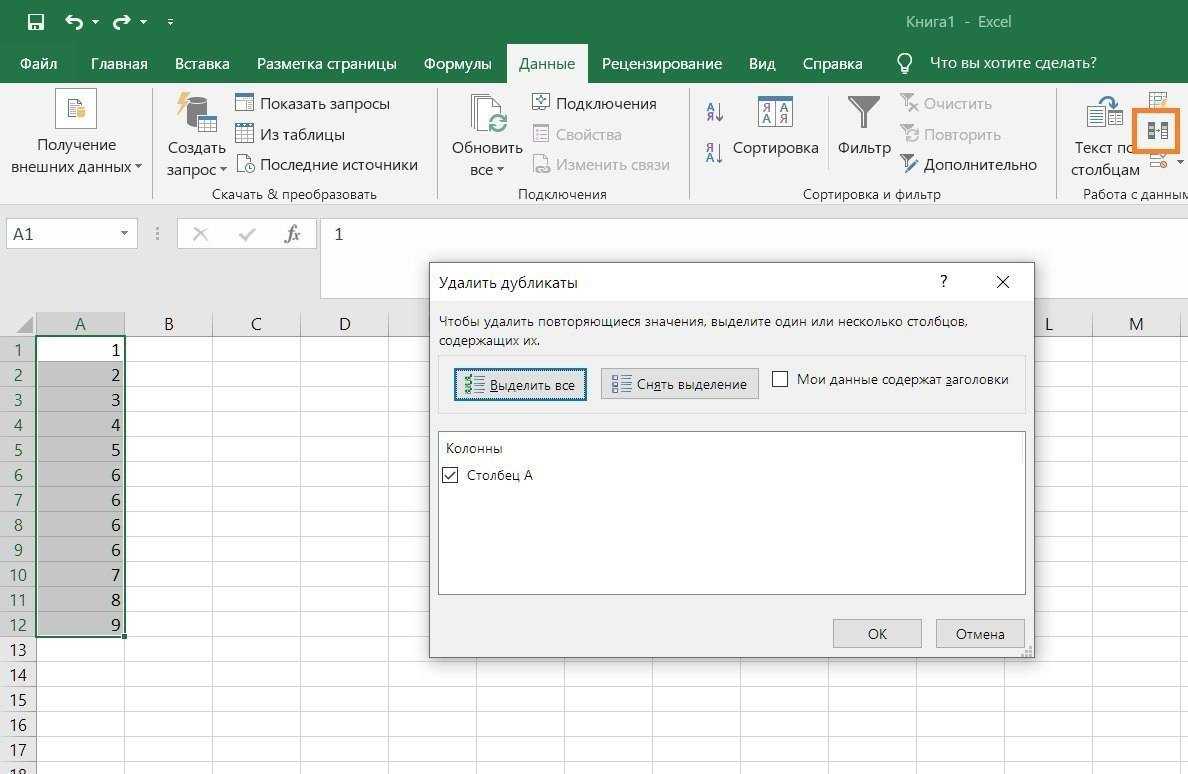
Предположим, у вас имеется таблица, состоящая из трех столбцов, в которой присутствуют одинаковые записи и вам необходимо избавится от них. Выделяем область таблицы, в которой хотите удалить повторяющиеся значения. Вы можете выделить один или несколько столбцов, или всю таблицу целиком. Переходим по вкладке Данные в группу Работа с данными, щелкаем по кнопке Удалить дубликаты.
Если в каждом столбце таблицы имеется заголовок, установить маркер Мои данные содержат заголовки. Также проставляем маркеры напротив тех столбцов, в которых требуется произвести поиск дубликатов.
Щелкаем ОК, диалоговое окно будет закрыто и строки, содержащие дубликаты будут удалены.
Данная функция предназначена для удаления записей, которые полностью дублируют строки в таблице. Если вы выделили не все столбцы для определения дубликатов, строки с повторяющимися значениями также будут удалены.
Макрос поиска ячейки с выпадающим списком
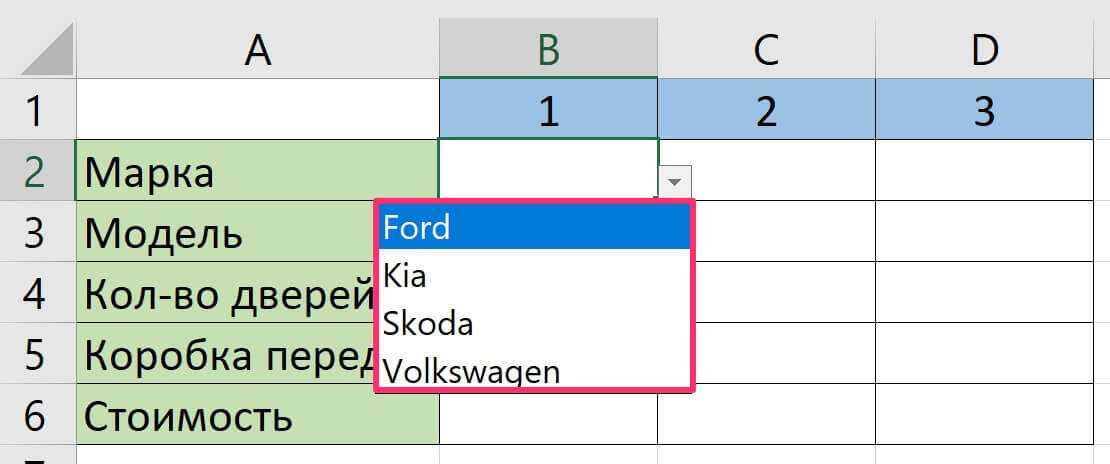
Допустим у нас имеется таблица Excel сформированная в результате экспорта журнала фактур из истории взаиморасчетов с клиентами фирмы, как показано ниже на рисунке:
Нам необходимо найти все выпадающие списки или определить каким ячейкам присвоена проверка вводимых данных, создана инструментом: «ДАННЫЕ»-«Работа с данными»-«Проверка данных».
В программе Excel по умолчанию есть встроенный инструмент для поиска ячеек с проверкой правил вводимых значений. Чтобы его использовать следует выбрать: ГЛАВНАЯ»-«Редактирование»-«Найти и выделить»-«Выделить группу ячеек». В появившемся диалоговом окне следует отметить опцию «проверка данных» и нажать на кнопку ОК. Но как всегда более гибким решением является написание своего специального макроса. Ведь в такие случаи всегда можно усовершенствовать инструмент и дописать много других полезных функций. А этот код макроса послужит прекрасным началом программы.
Откройте редактор макросов Visual Basic (ALT+F11) и создайте новый модуль выбрав в редакторе инструмент: «Insert»-«Module». В созданный модуль введите VBA код макроса:
Если нужно выделить все ячейки в таблице, которые содержат проверку вводимых значений включенной инструментом «Проверка данных», тогда выберите инструмент: «РАЗРАБОТЧИК»-«Код»-«Макросы»-«ProvDan»-«Выполнить».
В результате выделились 14 ячеек в столбце G, для которых включена проверка данных в стиле выпадающего списка:
В данном коде мы сначала выделяем все ячейки на текущем листе с помощью инструкции:
Cells.Select
После, определяем диапазон ячеек на листе, который использует исходная таблица и с которыми будет работать наш макрос. Чтобы определить диапазон таблицы на рабочем листе Excel, мы могли бы использовать свойство UsedRange при создании экземпляра объекта Range в переменной diapaz1. Данное свойство охватывает только непустые ячейки, а это может быть даже несмежный диапазон. Но таблица может содержать пустые ячейки для, которых присвоена проверка ввода значений. Чтобы наш макрос не игнорировал пустые ячейки внутри таблицы мы определяем смежный (неразрывный) диапазон, который начинается с ячейки A1 и заканчивается последней используемой ячейкой на рабочем листе Excel.
Set diapaz1 = Application.Range(ActiveSheet.Range(“A1”), ActiveSheet.Cells.SpecialCells(xlCellTypeLastCell))
Последняя ячейка находиться наиболее отдаленно от ячейки A1 (в данном примере – это G15) и была использована на листе (это обязательное условие). При чем использована в прямом смысле, она может даже не содержать значения, но иметь измененный числовой формат, другой цвет фона, другие границы, объединение и т.п. Чтобы найти последнюю используемую ячейку на листе стандартными средствами Excel, выберите инструмент: «ГЛАВНАЯ»-«Редактирование»-«Найти и выделить»-«Выделить группу ячеек».
В появившемся окне следует выбрать опцию «последнюю ячейку». А после просто нажать ОК. Курсор клавиатуры сразу переместиться на последнюю используемую ячейку на рабочем листе Excel.
Можно даже при создании экземпляра объекта Range в переменной diapaz1 использовать диапазон целого листа. Для этого просто замените выше описанную инструкцию на:
Set diapaz1 = Selection
Так на первый взгляд даже проще, но тогда макрос будет проверять все ячейки на листе и потребует больше ресурсов. Особенно если мы при изменении этой инструкции не удалим инструкцию выделения всех ячеек на листе Excel. Таким кодом макроса, можно существенно снизить производительность работы программы Excel при его выполнении. Поэтому так делать не рекомендуется. Проверяйте ячейки только те, которые были использованы на листе. Так вы получите в десятки раз меньший диапазон и выше производительность макроса.
Далее в коде макроса перед циклом прописана инструкция для выключения обработки ошибок, выполняемых в коде.
On Error Resume Next
Но после конца цикла обработка ошибок снова включается.
On Error GoTo 0
Внутри цикла проверяться по отдельности все ячейки на наличие включенной проверки вводимых значений инструментом «Проверка данных». Если ячейка содержит проверку вводимых значений?
If IsError(diapaz1(i).Validation.Type) Then
Тогда она присоединяется к диапазону ячеек, находящихся в переменной diapaz2.
Set diapaz2 = Application.Union(diapaz2, diapaz1(i))
В конце кода выделяется несмежный диапазон переменной diapaz2, который включает в себя все выпадающие списки на текущем рабочем листе Excel. И сразу же выводиться сообщение о количестве найденных и выделенных ячеек в этом же диапазоне.
MsgBox “Найдено: ” & diapaz2.Count & ” ячеек!”
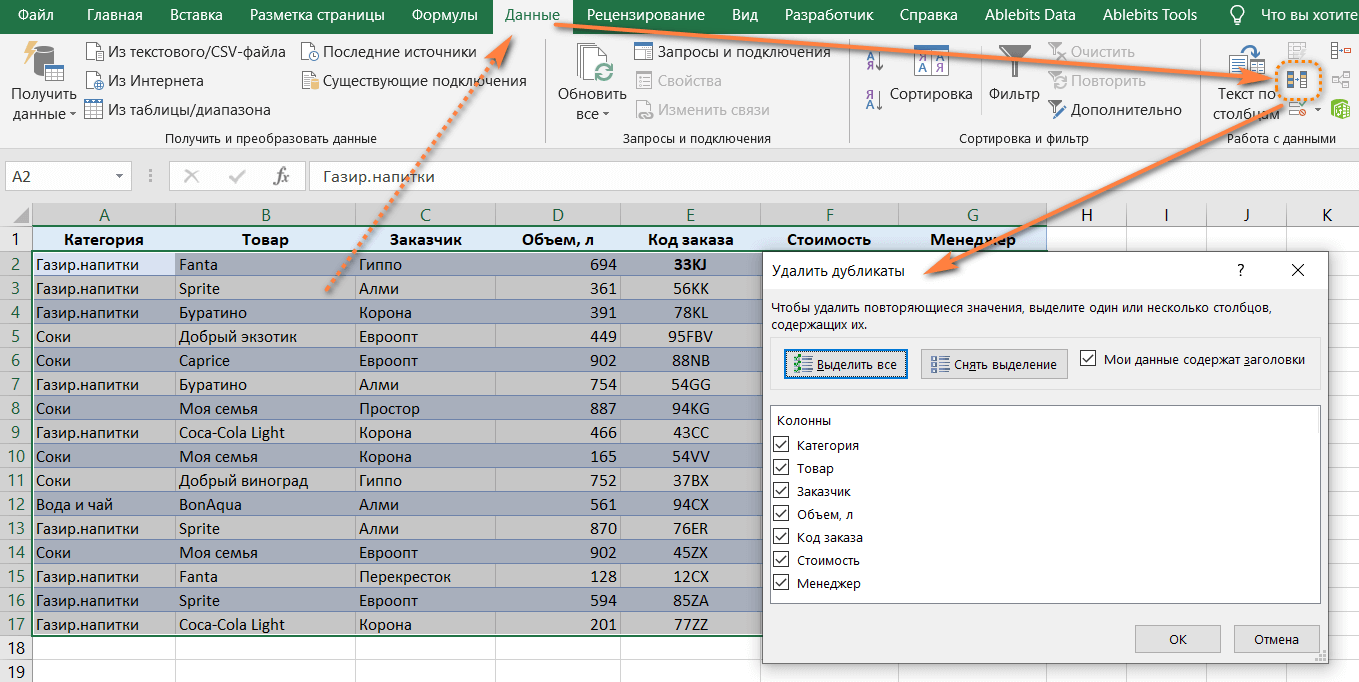
Еще один способ быстро удалить дубли в таблице
Этот способ удалит все одинаковые значения, которые встречаются в таблице. Если вам нужен поиск только в некоторых столбцах, то выделите их.
Теперь откройте вкладку «Данные», раздел «Работа с данными», «Удалить дубликаты».
Расставим нужные галочки. Мне нужен поиск по двум столбцам, потому оставляю, как есть, и жму на кнопку «ОК».
На этом метод закончился. Вот мой результат его работы.
Спасибо за прочтение. Не забывайте делиться с друзьями с помощью кнопок социальных сетей, и комментируйте.
Поиск дублей в Excel – это одна из самых распространенных задач для любого офисного сотрудника. Для ее решения существует несколько разных способов. Но как быстро как найти дубликаты в Excel и выделить их цветом? Для ответа на этот часто задаваемый вопрос рассмотрим конкретный пример.
Метод 2: удаление повторений при помощи “умной таблицы”
Еще один способ удаления повторяющихся строк – использование “умной таблицы“. Давайте рассмотрим алгоритм пошагово.
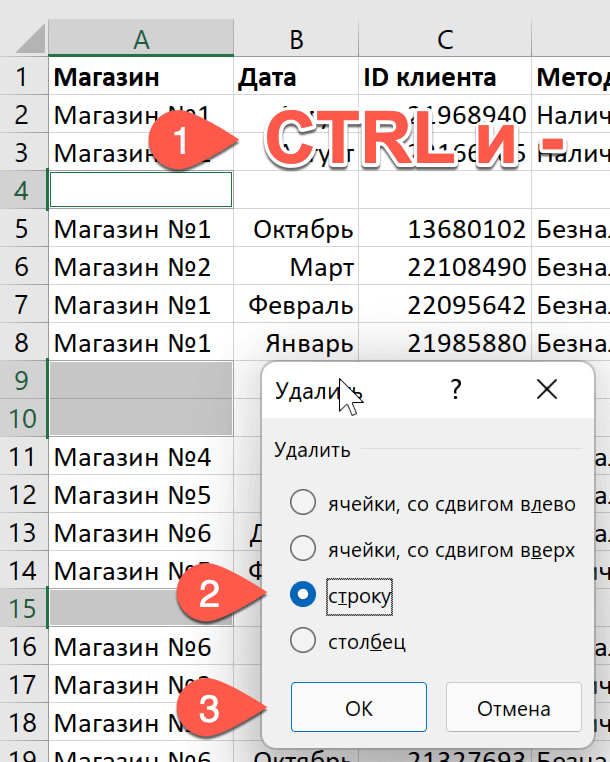


- Для начала, нам нужно выделить всю таблицу, как в первом шаге предыдущего раздела.
- Во вкладке “Главная” находим кнопку “Форматировать как таблицу” (раздел инструментов “Стили“). Кликаем на стрелку вниз справа от названия кнопки и выбираем понравившуюся цветовую схему таблицы.
- После выбора стиля откроется окно настроек, в котором указывается диапазон для создания “умной таблицы“. Так как ячейки были выделены заранее, то следует просто убедиться, что в окошке указаны верные данные. Если это не так, то вносим исправления, проверяем, чтобы пункт “Таблица с заголовками” был отмечен галочкой и нажимаем ОК. На этом процесс создания “умной таблицы” завершен.
- Далее приступаем к основной задаче – нахождению задвоенных строк в таблице. Для этого:
- ставим курсор на произвольную ячейку таблицы;
- переключаемся во вкладку “Конструктор” (если после создания “умной таблицы” переход не был осуществлен автоматически);
- в разделе “Инструменты” жмем кнопку “Удалить дубликаты“.
- Следующие шаги полностью совпадают с описанными в методе выше действиями по удалению дублированных строк.
Примечание: Из всех описываемых в данной статье методов этот является наиболее гибким и универсальным, позволяя комфортно работать с таблицами различной структуры и объема.
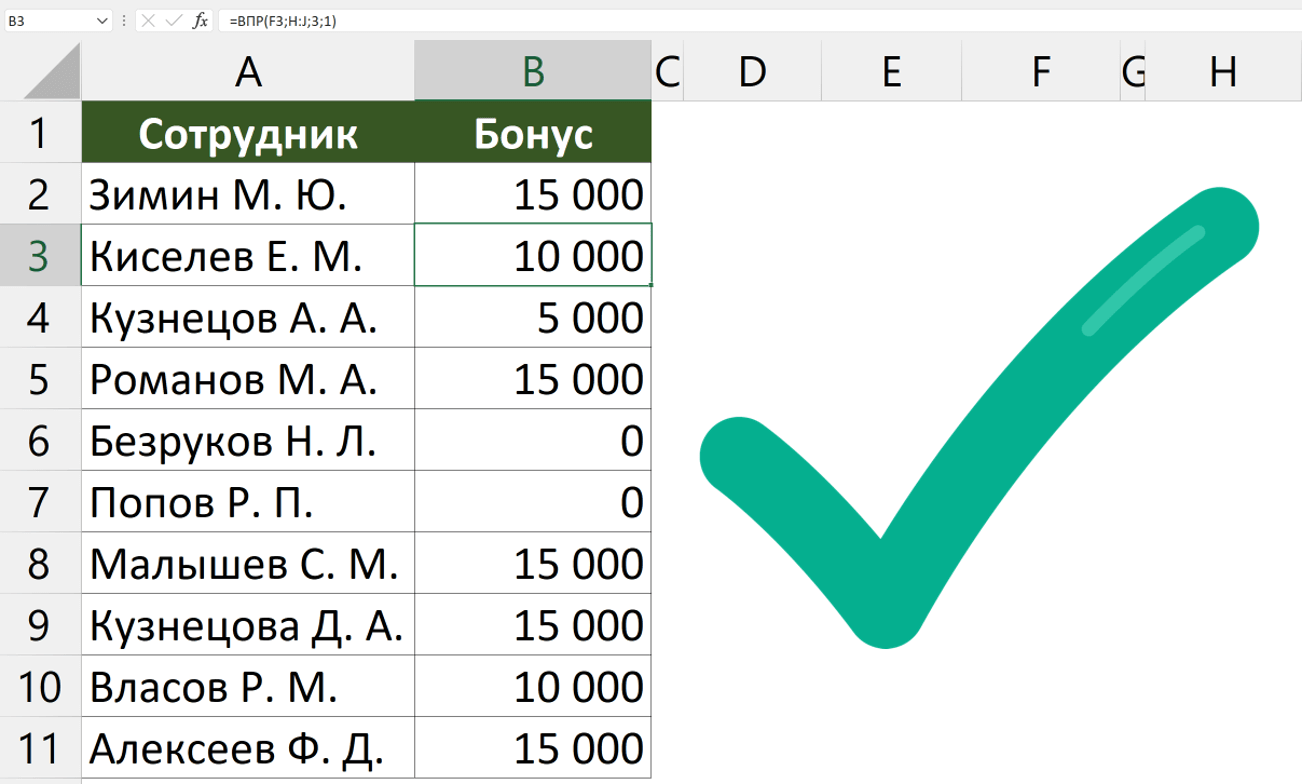
Поиск повторяющихся значений включая первые вхождения.
Предположим, у нас есть набор индикаторов в столбце A, среди которых, вероятно, есть такие же. Это могут быть номера заказов, названия продуктов, имена клиентов и другие данные. Если ваша задача — найти их, вам подойдет следующая формула:
Где A2 — первая ячейка области поиска.
Просто введите это выражение в любую ячейку и потяните вниз по всему столбцу, который вы хотите проверить на наличие дубликатов.
Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если есть совпадение. А для значений, которые встречаются только 1 раз, отображается ЛОЖЬ.
Запрос! Если вы ищете повторы в определенной области, а не во всем столбце, укажите желаемый диапазон и «зафиксируйте» его знаками $. Это значительно ускорит расчеты. Например, если вы смотрите в формате A2: A8, используйте
Если вас смущают значения ИСТИНА и ЛОЖЬ в столбце статуса и вы не хотите помнить, какое из них означает повторение, а какое уникально, заключите свой СЧЁТЕСЛИ в функцию ЕСЛИ и укажите любые слова, которые должны соответствовать повторяющимся и уникальным:
Если вам нужна формула для указания только дубликатов, замените «Уникальный» пробелом («»):
В этом случае Excel будет отмечать только неуникальные записи, оставляя пустую ячейку перед уникальными.
Поиск неуникальных значений без учета первых вхождений
Вы, наверное, заметили, что в приведенных выше примерах все совпадения упоминаются как дубликаты. Но часто задача состоит в том, чтобы найти только повторения, не трогая первые вхождения. То есть когда что-то впервые встречается, это точно еще не может быть дубликатом.
Если вам просто нужно указать совпадения, давайте немного изменим:
На скриншоте ниже вы можете увидеть эту формулу в действии.
легко понять, что это не означает первое вхождение слова, а отсчет начинается со второго.
Чувствительный к регистру поиск дубликатов
Я хотел бы обратить ваше внимание на то, что, хотя приведенные выше формулы находят 100% дубликатов, есть тонкий момент: они не чувствительны к регистру
Может, для тебя это не важно. Но если abc, abc и abc — три разных параметра в ваших данных, то этот пример для вас
Но если abc, abc и abc — три разных параметра в ваших данных, то этот пример для вас.
Как вы уже догадались, использованные нами ранее выражения не справятся с этой задачей. Здесь мы должны выполнить более тонкий поиск, в котором нам поможет следующая матричная функция:
Не забывайте, что формулы массива вводятся нажатием Ctrl + Shift + Enter.
Вернувшись к оглавлению, используйте функцию ТОЧНО, чтобы сравнить целевую ячейку со всеми другими ячейками в выбранной области. Результат возвращается как ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из единиц и нулей с помощью оператора (—).
Затем функция СУММ складывает эти числа. И если результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы посмотрите на снимок экрана ниже, вы можете убедиться, что поиск действительно чувствителен к регистру при обнаружении дубликатов:
Смородина и арбуз, которые встречаются дважды, в нашем поиске не помечаются, так как регистр их первых букв разный.





